Chapter 4 コホート研究
4.1 ロジステイック回帰
ロジステイック回帰は、1948年にアメリカにおいてフラミンガム研究(Framingham study)のために開発された統計手法です。 これは、冠状動脈性疾患に関する大規模なコホート研究でした。
一般的には、以下のような流れになります。
- 目的変数 \(y\) は、2値変数 (ex. 生 or 死) のオッズ比
- 単変量解析を行う
- 関連因子を同定する
- 多変量解析して、独立因子を決定する
関連因子の同定は、統計学的には単変量解析で p < 0.10 またはp < 0.15 のものを選ぶことがあります。このほか、先行文献などから関連があるとされているものを見つけることもあります。
ln OR\(_y\) = \(\alpha\) + ln OR\(_1\) \(\times\) \(x_1\) + ln OR\(_2\) \(x_2\) + \(\cdots\)
対数の底は自然対数 \(e\)。
OR \(_i\):
- \(x_i\) が2値変数の時(ex. 男=0 or 女=1)、\(y\) の男に対する女のオッズ比。 なお、3値以上の因数型 (A, B, C, …) の場合、(A, B), (A, C) … と2値変数に変換します。
- \(x_i\) が連続変数の時、\(y\) の \(x_i\) が1大きくなる時のオッズ比。
式を見てわかる通り、一つのアウトカム (\(y\)) を、複数の要因の多変量解析としています。 まず、OR\(_y\) は、アウトカムの発生オッズ比です。 \(x_i\) は、それぞれの説明変数です。
この式が論文中に出てくることはあまりありません。 通常は、表形式で以下のように示されているでしょう。
| OR | 95%CI | 型 | |
|---|---|---|---|
| 社会参加数 | 0.83 | (0.74-0.96) | 数値 |
| 性別 (女性) | 1.16 | (0.81-1.68) | 因子 |
| 年齢 $$65 | 1.11 | (0.75-1.62) | 因子 |
| BMI | 1.11 | (0.75-1.62) | 数値 |
| 喫煙 | 1.18 | (0.56-2.50) | 因子 |
上述の表の場合、以下のような解釈になります。 社会参加数が1増えると、イベント発生のオッズ比が0.83となります。 これは、95%信頼区間 (CI) が 1 を含んでおらず、有意差であると言えます。 年齢が1歳上がるとイベント発生のオッズ比が1.11となります、性別(女性)は、イベント発生のオッズ比が 1.16 となりますが、95%CIが 1 を含んでいるので、有意差があるとは言えないと判断します。
4.2 論文 Abe T (2020) PLoS One
今回は、実際に論文に掲載されたデータを使って、ロジスティック回帰分析を行ってみましょう。
- Abe T, Okuyama K, Kamada M, Yano S, Toyama Y, Isomura M, … & Miyazaki R (2020). Social participation and physical prefrailty in older Japanese adults: The Shimane CoHRE study. PloS one, 15(12), e0243548. https://doi.org/10.1371/journal.pone.0243548
この論文は、島根県隠岐の島において行われた横断研究です。高齢者は身体的・精神的に衰える「フレイル」という状態になりやすいですが、これを放置してしまいますと要介護状態になります。最近では、社会的参加が多い高齢者はフレイルになりにくいという研究もあります。とはいえ「社会参加」という言葉は漠然としていて人によって解釈が異なります。そこで、日本の農村部における社会参加をより詳しく調べてみました。
社会参加としては、ボランティア活動、運動、町会活動、宗教、地域の高齢者サロンに分けました。それぞれの参加頻度を聞き取りました。結果としては、社会参加が多いほどプレフレイルにはなりにくく、種類としては運動がプレフレイルになりにくく、町会活動はフレイルとプレフレイルになりにくいという結果となりました。
ここで用いている統計手法はロジスティック回帰です。社会参加については、OR = 0.83 (95% CI, 0.74–0.94)でした。 (OR = 0.47; 95% CI, 0.31–0.73)。 (OR = 0.57; 95% CI, 0.37–0.86)。
4.3 xlsx データの読み込み
library(curl)
library(readxl)
curl_download("https://doi.org/10.1371/journal.pone.0243548.s003", "journal_pone_0243548.xlsx")
dfFrailty <- read_excel("journal_pone_0243548.xlsx")この論文は、サイト上でエクセルファイルを提供しています。
curl ライブラリの curl_download 関数でダウンロードし、保存します。
なお、エクセルファイルへの URL は、論文サイト中にあります。
関数
- curl_download:
curlライブラリの関数。インターネット上からダウンロードし、指定したな目で保存する。 - read_excel: `readxl`` ライブラリの関数。.xslx ファイルを読み込む。
ライブラリ名が read_xl なのに、関数名が read_excel となっているのは、困ったものです。
データを確認すると、ところどころ NA (欠損値) があるものの、比較的正規化されたデータであることが分かります。
念のため、因子型データを因子として定義します。
dfFrailty$frailty <- as.factor(dfFrailty$frailty)
dfFrailty$volunteer <- as.factor(dfFrailty$volunteer)
dfFrailty$sports <- as.factor(dfFrailty$sports)
dfFrailty$neighborhood <- as.factor(dfFrailty$neighborhood)
dfFrailty$religious <- as.factor(dfFrailty$religious)
dfFrailty$salon <- as.factor(dfFrailty$salon)
dfFrailty$gender <- as.factor(dfFrailty$gender)
dfFrailty$smoking <- as.factor(dfFrailty$smoking)
dfFrailty$medication <- as.factor(dfFrailty$medication)
dfFrailty$age <- as.factor(dfFrailty$age)
dfFrailty$education <- as.factor(dfFrailty$education)
dfFrailty$working <- as.factor(dfFrailty$working)
dfFrailty$livingArrengement <- as.factor(dfFrailty$livingArrengement)同じことをなんども繰り返す時、通常はループ処理を行います。 本書では、極力プログラミング的なことを避けるため、同じ処理でもそのまま記述しています。
視覚的にも確認してみましょう。
library(GGally)
dfFrailtyImputed <- subset(dfFrailty, Imputation_Detaset == 7)
ggpairs(data = dfFrailtyImputed, columns = 9:14, mapping = aes(color = frailty))## Warning: Removed 60 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 60 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 60 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 60 rows containing non-finite values (stat_g_gally_count).## Warning: Removed 66 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 66 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 66 rows containing non-finite values (stat_g_gally_count).## Warning: Removed 71 rows containing non-finite values (stat_g_gally_count).
## Warning: Removed 71 rows containing non-finite values (stat_g_gally_count).## Warning: Removed 72 rows containing non-finite values (stat_g_gally_count).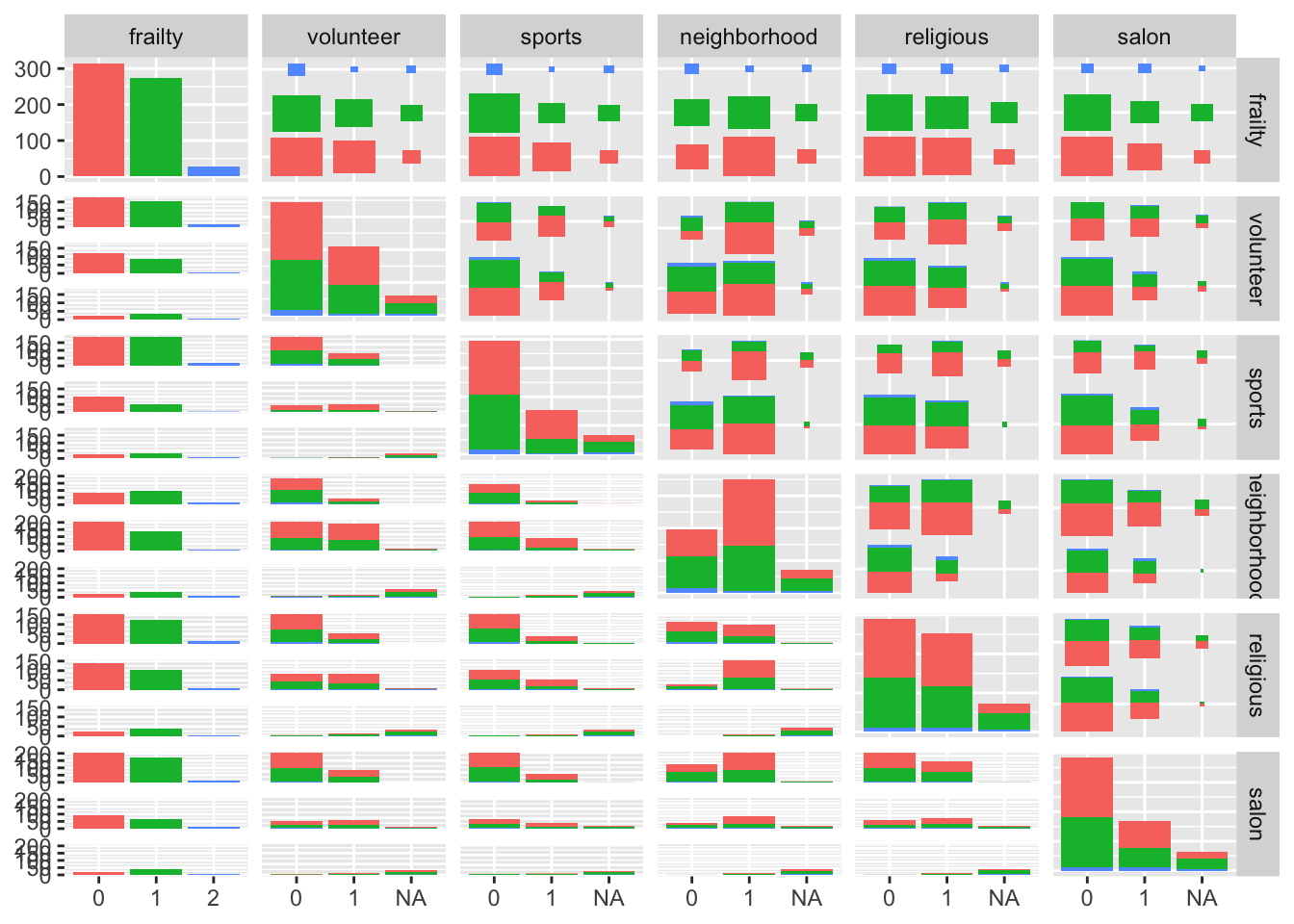
関数
- as.factor: base ライブラリの関数。数値型や文字型を因子 (factor) 型にする。
- ggpairs: GGally ライブラリの関数。R の基本 graphics パッケージの pairs を拡張している。
9:14 は、R 特有の表現で、c(9, 10, 11, 12, 13, 14) を意味します。
mapping = aes(color = frailty) の、frailty は dfFrailty の列名。frailty = 0, 1, 2 で、それぞれに色を割り当てる。
4.3.1 外れ値 (outlier) と代入 (imputation)
論文によると、代入 (imputation) をしたようなので、Imputation_Detaset という列があります。 どうやら、Imputation_Detaset == 1 となっているデータは代入前で、Imputation_Detaset == 7 となっているのが解析対象データのようです。
library(mice)
dfFrailtyImp0 <- subset(dfFrailty, Imputation_Detaset == 0)
dfFrailtyImp7 <- subset(dfFrailty, Imputation_Detaset == 7)
micePone0243548Imp0 <- mice(dfFrailtyImp0)
dfFrailtyImp0MICE <- complete(micePone0243548Imp0, 1)関数
- mice:
miceライブラリの関数。代入に関するオブジェクトを作成する。 - complete:
miceライブラリの関数。代入を行ってデータフレームを返す。
是非、上のコードを実行してみて、dfFrailtyImp0 と dfFrailtyImp0MICE を見比べてみてください。NA がなくなっていることが分かると思います。
代入前
代入後
4.4 表1の作成
library(tableone)
dfFrailty <- dfFrailtyImp10
CreateTableOne(data = dfFrailty,
strata="frailty",
vars=c("TotalSP","volunteer","sports", "neighborhood","religious","salon","gender","age","BMI","smoking","medication","education","working","livingArrengement"),
factorVars=c("volunteer","sports", "neighborhood","religious","salon","gender","age","smoking","medication","education","working","livingArrengement"))## Stratified by frailty
## 0 1 2 p
## n 315 273 28
## TotalSP (mean (SD)) 2.30 (1.48) 1.98 (1.41) 1.79 (1.42) 0.012
## volunteer = 1 (%) 118 (40.3) 89 (36.9) 4 (18.2) 0.109
## sports = 1 (%) 102 (35.1) 50 (21.0) 3 (14.3) 0.001
## neighborhood = 1 (%) 205 (71.2) 139 (58.9) 6 (28.6) <0.001
## religious = 1 (%) 137 (47.2) 106 (45.7) 10 (45.5) 0.935
## salon = 1 (%) 91 (31.1) 64 (27.1) 13 (54.2) 0.022
## gender = 2 (%) 127 (40.3) 97 (35.5) 8 (28.6) 0.292
## age = 2 (%) 168 (53.3) 135 (49.5) 3 (10.7) <0.001
## BMI (mean (SD)) 22.83 (3.15) 23.14 (3.03) 22.50 (3.59) 0.350
## smoking = 2 (%) 297 (94.3) 256 (93.8) 27 (96.4) 0.841
## medication (%) 0.108
## 0 54 (17.1) 66 (24.2) 8 (28.6)
## 1 125 (39.7) 98 (35.9) 13 (46.4)
## 2 136 (43.2) 109 (39.9) 7 (25.0)
## education (%) 0.011
## 1 104 (33.0) 76 (27.8) 4 (14.3)
## 2 118 (37.5) 98 (35.9) 7 (25.0)
## 3 93 (29.5) 99 (36.3) 17 (60.7)
## working = 2 (%) 87 (27.6) 74 (27.1) 4 (14.3) 0.308
## livingArrengement = 2 (%) 262 (83.2) 219 (80.2) 24 (85.7) 0.565
## Stratified by frailty
## test
## n
## TotalSP (mean (SD))
## volunteer = 1 (%)
## sports = 1 (%)
## neighborhood = 1 (%)
## religious = 1 (%)
## salon = 1 (%)
## gender = 2 (%)
## age = 2 (%)
## BMI (mean (SD))
## smoking = 2 (%)
## medication (%)
## 0
## 1
## 2
## education (%)
## 1
## 2
## 3
## working = 2 (%)
## livingArrengement = 2 (%)4.5 ロジスティック回帰解析
4.5.1 データ整形
frail (frailty = 2) を削除し、robust (frailty = 0) と prefrail (frailty = 1) だけにします。
dfFrailty <- subset(dfFrailty, frailty != '2')4.5.2 単変量解析
4.5.3 ロジスティック回帰
library("epiDisplay", warn.conflicts=FALSE, quietly=TRUE)
GlmFrailty <- glm(frailty ~ TotalSP,
family=binomial(logit),
data=dfFrailty)
summary(GlmFrailty)##
## Call:
## glm(formula = frailty ~ TotalSP, family = binomial(logit), data = dfFrailty)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.2563 -1.1260 -0.9427 1.2297 1.4319
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.18361 0.14802 1.240 0.21481
## TotalSP -0.15288 0.05766 -2.652 0.00801 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 812.14 on 587 degrees of freedom
## Residual deviance: 805.01 on 586 degrees of freedom
## AIC: 809.01
##
## Number of Fisher Scoring iterations: 4logistic.display(GlmFrailty)##
## Logistic regression predicting frailty : 1 vs 0
##
## OR(95%CI) P(Wald's test) P(LR-test)
## TotalSP (cont. var.) 0.86 (0.77,0.96) 0.008 0.008
##
## Log-likelihood = -402.5047
## No. of observations = 588
## AIC value = 809.0094関数
glm: stats ライブラリの関数。Generalized Linear Models (一般線形化モデル, GLM) を作成する。形式が独特で、“目的変数 ~ 説明変数1 + 説明変数2” という形式。多変量解析で用いる lm は二値変数を取らないのに対し、 glm は二値変数に対応している。
summary: base ライブラリの関数。モデルの統計値 (p 値や 95%信頼区間) などを返す。
GlmFrailtyM2 <- glm(frailty ~ TotalSP + gender + age + BMI + smoking + medication + education + working + livingArrengement,
family=binomial(logit),
data=dfFrailty)
summary(GlmFrailtyM2)##
## Call:
## glm(formula = frailty ~ TotalSP + gender + age + BMI + smoking +
## medication + education + working + livingArrengement, family = binomial(logit),
## data = dfFrailty)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.4964 -1.0925 -0.8905 1.2177 1.5817
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.29116 0.82077 0.355 0.72278
## TotalSP -0.16273 0.05933 -2.743 0.00609 **
## gender2 -0.17045 0.18704 -0.911 0.36214
## age2 -0.10833 0.19657 -0.551 0.58157
## BMI 0.02519 0.02796 0.901 0.36766
## smoking2 -0.19633 0.38229 -0.514 0.60756
## medication1 -0.42510 0.23318 -1.823 0.06830 .
## medication2 -0.43096 0.23769 -1.813 0.06982 .
## education2 0.08037 0.20768 0.387 0.69877
## education3 0.27247 0.22089 1.234 0.21739
## working2 0.01984 0.20712 0.096 0.92367
## livingArrengement2 -0.17658 0.22227 -0.794 0.42694
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 812.14 on 587 degrees of freedom
## Residual deviance: 794.00 on 576 degrees of freedom
## AIC: 818
##
## Number of Fisher Scoring iterations: 4logistic.display(GlmFrailtyM2)##
## Logistic regression predicting frailty : 1 vs 0
##
## crude OR(95%CI) adj. OR(95%CI) P(Wald's test)
## TotalSP (cont. var.) 0.86 (0.77,0.96) 0.85 (0.76,0.95) 0.006
##
## gender: 2 vs 1 0.82 (0.58,1.14) 0.84 (0.58,1.22) 0.362
##
## age: 2 vs 1 0.86 (0.62,1.18) 0.9 (0.61,1.32) 0.582
##
## BMI (cont. var.) 1.03 (0.98,1.09) 1.03 (0.97,1.08) 0.368
##
## smoking: 2 vs 1 0.91 (0.46,1.81) 0.82 (0.39,1.74) 0.608
##
## medication: ref.=0
## 1 0.64 (0.41,1) 0.65 (0.41,1.03) 0.068
## 2 0.66 (0.42,1.02) 0.65 (0.41,1.04) 0.07
##
## education: ref.=1
## 2 1.14 (0.76,1.69) 1.08 (0.72,1.63) 0.699
## 3 1.46 (0.97,2.19) 1.31 (0.85,2.02) 0.217
##
## working: 2 vs 1 0.97 (0.68,1.4) 1.02 (0.68,1.53) 0.924
##
## livingArrengement: 2 vs 1 0.82 (0.54,1.25) 0.84 (0.54,1.3) 0.427
##
## P(LR-test)
## TotalSP (cont. var.) 0.006
##
## gender: 2 vs 1 0.362
##
## age: 2 vs 1 0.582
##
## BMI (cont. var.) 0.367
##
## smoking: 2 vs 1 0.608
##
## medication: ref.=0 0.133
## 1
## 2
##
## education: ref.=1 0.447
## 2
## 3
##
## working: 2 vs 1 0.924
##
## livingArrengement: 2 vs 1 0.427
##
## Log-likelihood = -397.0016
## No. of observations = 588
## AIC value = 818.0032参照(性別の場合、「男」か「女」)が違うのか、値が論文とは一致しません。 relevel 関数を使って、性別の参照を 2 に変えてみます。
dfFrailty$gender <- relevel(dfFrailty$gender, ref=2)
dfFrailty$age <- relevel(dfFrailty$age, ref=2)
dfFrailty$smoking <- relevel(dfFrailty$smoking, ref=2)
dfFrailty$medication <- relevel(dfFrailty$medication, ref=2)
dfFrailty$education <- relevel(dfFrailty$education, ref=3)
dfFrailty$working <- relevel(dfFrailty$working, ref=2)
dfFrailty$livingArrengement <- relevel(dfFrailty$livingArrengement, ref=2)
GlmFrailtyM3 <- glm(frailty ~ TotalSP + gender + age + BMI + smoking + medication + education + working + livingArrengement,
family=binomial(logit),
data=dfFrailty)
summary(GlmFrailtyM3)##
## Call:
## glm(formula = frailty ~ TotalSP + gender + age + BMI + smoking +
## medication + education + working + livingArrengement, family = binomial(logit),
## data = dfFrailty)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.4964 -1.0925 -0.8905 1.2177 1.5817
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.493316 0.751555 -0.656 0.51157
## TotalSP -0.162733 0.059325 -2.743 0.00609 **
## gender1 0.170448 0.187039 0.911 0.36214
## age1 0.108332 0.196574 0.551 0.58157
## BMI 0.025186 0.027958 0.901 0.36766
## smoking1 0.196332 0.382292 0.514 0.60756
## medication0 0.425100 0.233181 1.823 0.06830 .
## medication2 -0.005858 0.197126 -0.030 0.97629
## education1 -0.272474 0.220895 -1.234 0.21739
## education2 -0.192105 0.210573 -0.912 0.36161
## working1 -0.019844 0.207124 -0.096 0.92367
## livingArrengement1 0.176581 0.222272 0.794 0.42694
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 812.14 on 587 degrees of freedom
## Residual deviance: 794.00 on 576 degrees of freedom
## AIC: 818
##
## Number of Fisher Scoring iterations: 4logistic.display(GlmFrailtyM3)##
## Logistic regression predicting frailty : 1 vs 0
##
## crude OR(95%CI) adj. OR(95%CI)
## TotalSP (cont. var.) 0.86 (0.77,0.96) 0.85 (0.76,0.95)
##
## gender: 1 vs 2 1.23 (0.88,1.71) 1.19 (0.82,1.71)
##
## age: 1 vs 2 1.17 (0.84,1.62) 1.11 (0.76,1.64)
##
## BMI (cont. var.) 1.03 (0.98,1.09) 1.03 (0.97,1.08)
##
## smoking: 1 vs 2 1.1 (0.55,2.17) 1.22 (0.58,2.57)
##
## medication: ref.=1
## 0 1.56 (1,2.44) 1.53 (0.97,2.42)
## 2 1.0223 (0.7095,1.473) 0.9942 (0.6756,1.463)
##
## education: ref.=3
## 1 0.69 (0.46,1.03) 0.76 (0.49,1.17)
## 2 0.78 (0.53,1.15) 0.83 (0.55,1.25)
##
## working: 1 vs 2 1.03 (0.71,1.48) 0.98 (0.65,1.47)
##
## livingArrengement: 1 vs 2 1.22 (0.8,1.85) 1.19 (0.77,1.84)
##
## P(Wald's test) P(LR-test)
## TotalSP (cont. var.) 0.006 0.006
##
## gender: 1 vs 2 0.362 0.362
##
## age: 1 vs 2 0.582 0.582
##
## BMI (cont. var.) 0.368 0.367
##
## smoking: 1 vs 2 0.608 0.608
##
## medication: ref.=1 0.133
## 0 0.068
## 2 0.976
##
## education: ref.=3 0.447
## 1 0.217
## 2 0.362
##
## working: 1 vs 2 0.924 0.924
##
## livingArrengement: 1 vs 2 0.427 0.427
##
## Log-likelihood = -397.0016
## No. of observations = 588
## AIC value = 818.0032関数
- relevel: stats ライブラリの関数。因子 (factor) 型で、ref となる変数を設定する。See https://stat.ethz.ch/R-manual/R-devel/library/stats/html/relevel.html
4.6 モデルの評価
4.6.1 多重共線性 (multicollinearity)
Model 3 の多重共線性を調べる。
library(car, warn.conflicts=FALSE, quietly=TRUE)
vif(GlmFrailtyM3)## GVIF Df GVIF^(1/(2*Df))
## TotalSP 1.041654 1 1.020615
## gender 1.166296 1 1.079952
## age 1.368763 1 1.169941
## BMI 1.063765 1 1.031390
## smoking 1.178558 1 1.085614
## medication 1.150842 2 1.035748
## education 1.134117 2 1.031964
## working 1.209635 1 1.099834
## livingArrengement 1.049269 1 1.024338vif: car パッケージの関数。
なお、VIF 値を求める関数は、多くのパッケージで提供されています。
具体的には、AED (corvif), car, rms, DAAG.
この表の一番右側を見ます。
- Fox J & Monette G (1992) Generalized Collinearity Diagnostics, JASA, 87, 178-183.
VIF 値の解釈は、多変量解析の場合、10以下で適切、10以上は多重共線性により不適切となります。ただし、ロジスティック回帰では、VIF の解釈はできないとする論文や、2.5 以下が適切とする論文もあります。(要確認)
4.7 判別率 (C統計量)
- あまり使われてはいない。
- ROC曲線の AUC を示す。
- 判別率を示す。高い方が良い。
4.8 サンプルサイズ
単変量
- WebPower
- powerMediation
wp.logistic(p0 = 0.4, p1 = 0.5, alpha = 0.05, power = 0.80) SSizeLogisticBin(p1 = 0.4, p2 = 0.5, B = 0.5, alpha = 0.05, power = 0.80)
多変量
最低限必要なイベント発生サンプル数 = 説明変数の数 × 10
イベント発生率が0.5であれば、これに2をかける必要がある。
Peduzzi P, Concato J, Kemper E, Holford TR, Feinstein AR (1996) A simulation study of the number of events per variable in logistic regression analysis.: J Clin Epidemiol, 49(12):1373-9.
- pwr2ppl
- samplesizelogisticcasecontrol